原则
要使用谷歌翻译官方API,您需要先付费获取Key。 如果Key不合法, API会返回错误禁止使用。 那么如何绕过Key验证呢? 有后门吗? 相反,光明正大地走前门,即直接抓取谷歌翻译网站的结果。
我们用浏览器谷歌翻译hello world并抓包,发现浏览器访问了这个URL:
%
很容易看出,源文本直接编码在 URL 中作为文本参数。 对应的tl参数表示,这里是zh-CN(简体中文)。
谷歌翻译返回:
{"":[{"trans":"你好世界!","orig":"你好世界!","":"世杰,你好!","":""},{"trans" :"很高兴见到你。","orig":"很高兴见到你。","":"Rènshi nǐ hěn gāoxìng。","":""}],"src":"en","" :48 }
格式与 JSON 类似,但不是标准的。 它不仅包含翻译结果,还包含汉语拼音和源文本语言等附加信息。 据推测,这些可能是为了客户端的一些特殊功能。
这个过程非常简单。 我们的爬虫逻辑是
首先将源文本和目标语言组成类似于上面的URL,然后使用谷歌翻译网站上的HTTP GET结果获取返回的数据,然后分别提取翻译结果。
需要注意的一点是不太喜欢爬虫:)它会禁止所有User-Agent为-/2.7的HTTP请求。 我们需要将自己伪装成浏览器 User-Agent: /4.0 来安抚 。 另一个提示是,您可以将URL中的参数从t更改为其他值,并且将返回标准JSON格式,以方便解析结果。
优化
虽然爬虫工作正常,但是存在两个问题:
短问题可以通过自动分割和多次查询来解决:对于长文本,文本会按标点、换行等间隔分割成多个接近2000字节的子文本,然后逐条查询,最后翻译结果将被拼接并返回。 用户。 这样就超出了文本长度限制。
慢的问题比较棘手,性能卡在网络延迟上。 官方API可以一次传入多个文本进行批量翻译,大大减少HTTP网络响应。 还支持批量翻译。 由于一次查询中最多允许 2000 字节的文本,因此请尝试尽可能多地使用。 用户输入多个文本后,多个小文本将被拼接成不超过2000字节的大文本,然后通过HTTP请求进行翻译。 最后将结果分割成几个对应的翻译文本并返回。
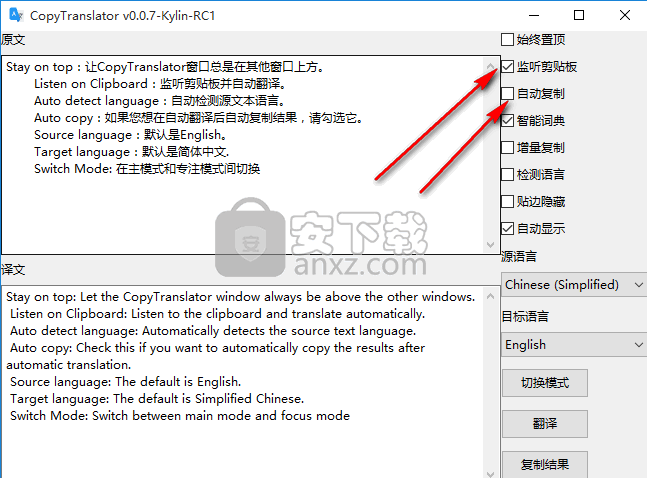
正如您在这里所看到的,批量查询和长文本支持完全相反。 批量查询需要拼接成大块,然后翻译一次结果,而长文本支持需要拆分,多次翻译,然后将结果拼接在一起。 如果批量查询中的某个文本过长,会先将其分割,然后与其前后较小的文本合并。 看起来逻辑有点复杂,但其实只要合理分层实现功能即可:
底层.()专门负责通过HTTP请求翻译单个文本。 不支持长文本拆分。 .xt() 通过基于 () 自动拆分多个查询来支持长文本。 拼接后调用最后一个外部API .()。 xt() 支持批量翻译
通过三层递进,将复杂的分割和拼接逻辑完美表达。 All in 可以通过一层额外的间接解决一切,没有欺骗的余地。
另一种加速方法是利用并发性。 内部使用线程池来并发处理多个HTTP请求,大大加快查询速度。 这里没有选择重新发明轮子,而是直接使用库提供的线程池。
批处理和并发的效果非常明显。 8000个短句的翻译时间从2小时缩短到10秒。 速度提升了700倍。 看起来不仅免费,而且比官方的API高效很多。
设计
它能工作,性能高,进一步的要求是使用方便。 这就涉及到API设计问题。 API的总体设计原则是简单但不粗暴(Make as,but not)
功能虽然简单,但细节决定成败。 比如传入传出参数的字符编码、代理设置、超时处理、并发线程数等应该如何合理组织和规划? 根据设计原则,我们将灵活性分为三大类并区别对待:
还有其他设计考虑因素:
开源
如果只是自己使用的话,没必要那么仔细考虑API。 之所以精心打造,目标就是开源! 社区非常支持开源。 开源库只需要按照一定的规范来操作:
选择版权:选择了很久,选择了免费的MIT代码管理:托管在 上,虽然名气不大,但优点是可以使用我最喜欢的hg单元测试:自动化单元测试是必要的,不仅既要对用户负责,又要让人可以放手,优化自己。 标准框架效果很好。 还添加了文档:使用社区标准文档工具生成,可以自动从代码中提取信息来生成文档。 文档生成后,可以免费上传到托管部署:只需按照规则在setup.py中写入元信息,打包代码并上传到pypi(详细步骤在这里)。 这样全世界的用户都可以使用pip或者安装它。 为了接触到更广泛的受众,我同时也花了一些力气去支持和推广:酒香也怕巷子深,更何况我这个小小的开源库。这也是原创本文的意图
回顾一下,总共有700行代码,其中只有300行是实际的功能代码。 其余 400 行包括 150 行文档注释和 250 行单元测试。 图书馆虽小,但如果一切都需要做好,工作量却比预想的要大得多。 总的来说,编写功能代码所花费的时间远远少于做开源外围辅助工作所花费的时间。
世界上的每一件事都必须用心去做,相信吧!
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏