
背景
所谓机器翻译可以看如下图:
我们的翻译机是一个黑盒子,里面有一个问号。 其功能是将一个语言序列(如以years为单位的has)转换为目标语言序列(如La sest ces)。 其中,翻译机在正式工作之前可以利用现有的语料库()进行学习和训练。
所谓神经网络机器翻译,就是利用神经网络来实现上述的黑盒翻译机。 许多基于神经网络的技术都源自那篇开创性的论文(神经网络的语言模型)。 其架构如下图所示:
其中,我们用神经网络代替了上图中的黑盒子。 神经网络中存在大量的链接权重,这些权重就是我们需要通过数据来训练和学习的参数。 经过训练的神经网络可以将输入源语言转换为输出目标语言。 我们希望神经网络学习的目标是能够准确翻译。 这里的准确度是指机器生成的句子更符合我们人类的说话习惯。 这里的log p(f|e)指的是给定源语言后机器生成语言f的概率。 我们希望这个概率对于实际数据来说尽可能大。 这就是所谓的语言模型。
基于神经网络的机器翻译模型的最大优点之一是它不需要我们使用复杂的特征工程来设计过程中的环节,这就是所谓的(端到端)模型。 这样的模型设计还可以避免中间环节误差的积累。
近年来神经机器翻译的准确率不断提高,尤其是2016年GNMT的突破。GNMT涉及的主要技术包括:
我们这节课主要介绍了前面的四项基础技术,它们都代表了深度学习人工智能技术的最前沿。 最后一个辅助手段是属于锦上添花的技术。
编码-解码框架
编码-解码框架如上图所示,其中 - W的左侧是编码器,右侧是解码器。 A、B、C表示源语言的输入序列,X、Y、Z表示翻译机给出的目标语言的输出序列。 表示句子的结束符。 W是编码器对输入语言序列A、B、C的编码向量。图中的每个方框代表一个随时扩展的RNN(或LSTM)神经网络。
这种编码-解码结构模拟了人脑的翻译过程,即先将听到的语言存储在大脑中,然后根据大脑中的理解给出目标语言的输出。 这里,W向量模拟了大脑中存储的源语言对应的向量。
该架构还将语言理解和语言模型结合起来,最终实现端到端机器翻译。 此外,这种编解码结构极其灵活,可以应用于图像标注、视频、文字等任务。 此外,该架构还可以很好地与外部语料库结合,具有良好的可扩展性。
编码器
该图显示了编码器的详细架构。 这里从下到上分为三层。 第一层是词向量嵌入。 它可以根据输入的词向量查找编码表得到压缩维度的词表示向量(第二层),然后输入到第三层。 这是 RNN 循环单元的状态。
解码器
接下来我们看看解码端。 这里,底部紫色节点表示编码器计算出的隐藏层节点状态,相当于输入源语言的编码向量。 之后,我们将这些信息输入到解码器的RNN单元,然后到第二层,解码器根据RNN单元计算概率向量。 即每个单词在目标语言词汇上出现的概率是多少。 最后,在第三层,我们根据计算出的概率样本生成目标语言。
然而,当我们回顾整个编码-解码过程时,我们会发现机器翻译的本质是先将源语言中的句子编码为向量,然后将向量映射到目标语言。 然而这种编码是将句子压缩成一个向量,显然会丢失很多信息。 因此,我们需要引入一种新的机制来解决这个问题。
注意机制
为了解决解码器引入的信息过度压缩的问题,引入注意力机制来解决该问题。 这里,在编码器和解码器之间添加了注意力机制。 如下所示:
编码器首先将编码后的信息输入到注意力机制,然后注意力机制将处理后的代码传递给解码器。 那么,注意力机制是如何运作的呢? 我们看下图:
在这张图中,我们展示了将法语句子翻译成英语句子的过程,其中的连接代表两种语言在单词层面上的对应和关联,例如法语对应英语是。 由于两种语言中单词的词序不同,所以当我们按照给定的顺序翻译一个单词时,首先要找出源语言中的哪个单词与该单词相关。 那么注意力机制就解决了这个问题。
所谓注意力机制,其实就是一种动态分配权重的机制。 如下所示:
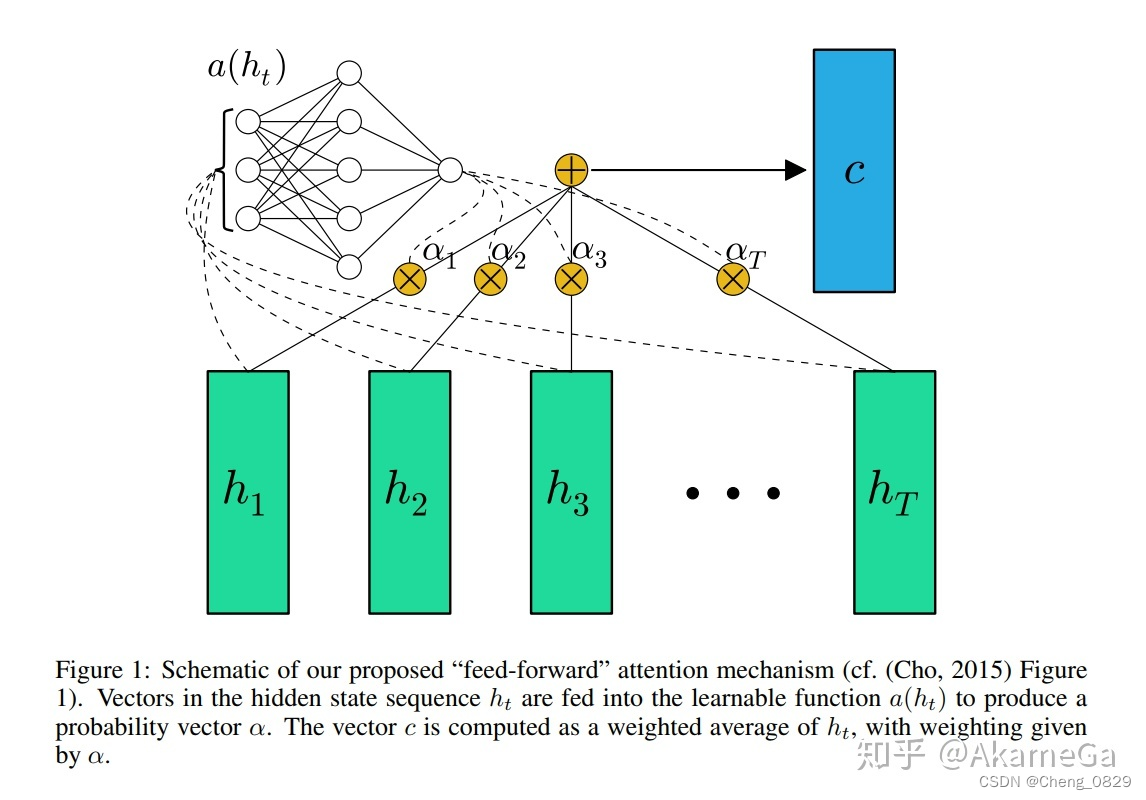
这里h1,h2,...,hT表示解码器接收到源语言向量x1,x2,...,xT时得到的隐藏层状态向量。 为了尽可能保留信息,人们使用双向RNN,即分别从正向和反向读取原始单词序列,并计算隐藏层的状态向量。 然后,我们将这些正向向量和反向向量进行相应的分组,即对同一个输入词的正向读取和反向读取得到的先前信息进行编码。 之后,注意力机制将为这些状态向量分配权重,这些权重为at,1,at,2,..,at,T。 对隐藏层的状态向量进行加权求和,得到输入到解码器的向量。 应该注意的是,这些权重 T 随时间 t 动态变化。 那么,at,T的值是如何取的呢? 在GNMT中,权重根据以下函数计算:
其中是一个从整个机器的输入信息和输出信息决定注意力分配权重的函数,也是一个可以训练的神经网络。 这里yi-1是解码器的输出,xt是网络的输入,由st经过接下来两步变换得到最终的权值向量ai。
事实上,注意力机制现在已经是一种通用机制,广泛应用于其他领域。 例如:
该图显示了机器在进行阅读理解时对文章不同短语部分的注意力分配权重。
这张图展示了机器在做图片标注时注意力在图像不同区域的分布情况。 其中,左上角是原始输入图片,后续的每张图片是机器吐出不同标签词(显示在图片左上角)时对该图片的注意力分布。
我们将在下一课中解释记忆机制。 在这里,我们引入第三种机制:残差网络。
残差网络 ( )
所谓残差网络,就是一种跨层级的链接机制。 如上图所示,灰粉色阴影部分就是采用残差网络机制的网络链路。 注意,在原始网络中,每个跨层链接只链接上下层,但这里从x10到+的链接就是这个跨层残差网络机制链接。
通过这种跨级链接的机制,可以将网络做得很深,从而实现深度的革命,并且可以显着降低准确率。 那么,残差网络是如何在加速网络学习的同时实现这种跨级链接的呢? 我们看下图:
我们知道,神经网络实际上是一个从输入到输出的函数。 那么对于一个本地的二层网络来说,也可以算是一个小功能了。 我们不妨记住这个小网络是 H(x),这正是我们的两层网络将学习的函数。
我们不妨将这个函数分解为两部分,一部分是从输入端直接输入的信号x,一部分是剩余量(残差)F(x),而这部分残差F(x)可以交给这两层网络来学习。 这样,当我们的网络逼近F(x)函数时,我只需要加上输入信号x,自然就得到了我们想要的函数H(x)。
那么,为什么我们要把 H(x) 分成 F(x) 和 x 呢? 答案是,当我们直接将输入信号x导入到输出节点+时,我们实际上创建了一条信息传输的捷径,这可以大大节省训练这个局部小网络的时间。 当然,这里的前提是,在大多数情况下,正确的H(x)函数与信号x具有相似的数量级。 因此,在我们创建捷径后,网络只需要进行微调即可学习实现残差函数 F(x) 的神经网络。
有了这种残差机制,我们就可以让信息更快地通过网络,这就大大节省了网络训练的时间,这自然就可以让我们加深网络的层次,这就是残差网络的基础。 原则。
有了残差机制,目前的网络深度可以达到1000层。
特殊支持机制
这种特殊的辅助机制是华为诺亚方舟提出的一项特殊技术,它需要解决的问题是避免过度翻译或欠翻译的问题。 所谓过度翻译是指某些词语或短语在译文中重复出现,而欠译或遗漏则是指某些词语没有得到有效翻译。
如上图所示,这个机制就是用一个向量来记录哪些单词已经翻译了,哪些单词没有翻译,然后将这个向量传递给注意力机制,注意力机制会自动学习得到一个正确的输入和输出,因此要注意遗漏和重复的单词。 图中Ci是cover()向量。
结尾
最后,结合上面提到的各种机制后,机器翻译的准确性得到了刷新。
如上图所示,这是GNMT在各种语言对之间的翻译准确率的比较。 其中,橙色柱的高度是人类的水平,绿色柱的高度是模型的水平,蓝色柱的高度是经典短语模型的水平。 我们可以看到,虽然人类的准确率还遥遥领先,但GNMT的水平已经超越了英语。 - 西班牙语和法语-英语翻译接近人类表现。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏

